Overview
Teaching: 30 min
Exercises: 0 minQuestions
How can I repeat the same operations on multiple values?
Objectives
Explain what a for loop does.
Correctly write for loops that repeat simple commands.
Trace changes to a loop variable as the loops runs.
Use a for loop to process multiple files
Recall that we have to do this analysis for every one of our dozen datasets, and we need a better way than typing out commands for each one, because we’ll find ourselves writing a lot of duplicate code. Remember, code that is repeated in two or more places will eventually be wrong in at least one. Also, if we make changes in the way we analyze our datasets, we have to introduce that change in every copy of our code. To avoid all of this repetition, we have to teach Octave to repeat our commands, and to do that, we have to learn how to write loops.
Suppose we want to print each character in the word “lead” on
a line of its own. One way is to use four disp statements:
word = 'lead';
disp(word(1));
disp(word(2));
disp(word(3));
disp(word(4));
l
e
a
d
But this is a bad approach for two reasons:
-
It doesn’t scale: if we want to print the characters in a string that’s hundreds of letters long, we’d be better off typing them in.
-
It’s fragile: if we change
wordto a longer string, it only prints part of the data, and if we change it to a shorter one, it produces an error, because we’re asking for characters that don’t exist.
word = 'tin';
disp(word(1));
disp(word(2));
disp(word(3));
disp(word(4));
error: A(I): index out of bounds; value 4 out of bound 3
There’s a better approach:
word = 'lead';
for letter = 1:4
disp(word(letter))
end
l
e
a
d
This improved version uses a for loop to repeat an operation—in this case, printing to the screen—once for each element in an array.
The general form of a for loop is:
for variable = collection
do things with variable
end
The for loop executes the commands in the
loop body
for every value in the array collection.
This value is called the loop variable,
and we can call it whatever we like.
In our example, we gave it the name letter.
We have to terminate the loop body with the end keyword,
and we can have as many commands as we like in the loop body.
But, we have to remember
that they will all be repeated as many times as
there are values in collection.
Our for loop has made our code more scalable, and less fragile. There’s still one little thing about it that should bother us. For our loop to deal appropriately with shorter or longer words, we have to change the first line of our loop by hand:
word = 'tin';
for letter = 1:3
disp(word(letter));
end
t
i
n
Although this works, it’s not the best way to write our loop:
-
We might update
wordand forget to modify the loop to reflect that change. -
We might make a mistake while counting the number of letters in
word.
Fortunately, Octave provides us with a convenient function to write a better loop:
word = 'aluminum';
for letter = 1:length(word)
disp(word(letter));
end
a
l
u
m
i
n
u
m
This is much more robust code,
as it can deal identically with
words of arbitrary length.
Here’s another loop that
repeatedly updates the variable len:
len = 0
for vowel = 'aeiou'
len = len + 1;
end
disp(['Number of vowels: ', num2str(len)])
It’s worth tracing the execution of this little program step by step.
Since there are five characters in “aeiou”,
the loop body will be executed five times.
When we enter the loop, len is zero -
the value assigned to it beforehand.
The first time through,
the loop body adds 1 to the old value of len,
producing 1,
and updates len to refer to that new value.
The next time around,
vowel is e,
and len is 1,
so len is updated to 2.
After three more updates,
len is 5;
since there’s nothing left in aeiou for Octave to process,
the loop finishes and the disp statement tells us our final answer.
Note that a loop variable is just a variable that’s being used to record progress in a loop. It still exists after the loop is over, and we can re-use variables previously defined as loop variables as well:
disp(vowel)
u
Performing Exponentiation
Octave uses the caret (
^) to perform exponentiation:disp(5^3)125You can also use a loop to perform exponentiation. Remember that
b^xis justb*b*b*…xtimes.Let a variable
bbe the base of the number andxthe exponent. Write a loop to computeb^x. Check your result forb = 4andx = 5.
Incrementing with Loops
Write a loop that spells the word “aluminum,” adding one letter at a time:
a al alu alum alumi alumin aluminu aluminum
Looping in Reverse
In Matlab, the colon operator (
:) accepts a stride or skip argument between the start and stop:disp(1:3:11)1 4 7 10disp(11:-3:1)11 8 5 2Using this, write a loop to print the letters of “aluminum” in reverse order, one letter per line.
m u n i m u l a
We now have almost everything we need to process
multiple data files with our analyze script.
You’ll notice that our data files are named
inflammation-01.csv, inflammation-02.csv, etc.
Let’s write a loop that tries to print the names of each one of our files:
for idx = 1:12
file_name = sprintf('inflammation-%d.csv', idx);
disp(file_name);
end
inflammation-1.csv
inflammation-2.csv
inflammation-3.csv
inflammation-4.csv
inflammation-5.csv
inflammation-6.csv
inflammation-7.csv
inflammation-8.csv
inflammation-9.csv
inflammation-10.csv
inflammation-11.csv
inflammation-12.csv
This is close, but not quite right.
The sprintf function is useful when we want to
generate Octave strings based on a template.
In our case,
that template is the string inflammation-%d.csv.
sprintf
generates a new string from our template by
replacing the %d with
the data referred to by our second argument, i.
Again, let’s trace the execution of our loop:
in the beginning of our loop,
i starts by referring to the value 1.
So, when Octave executes the command
file_name = sprintf('inflammation-%d.csv', idx);
it substitutes the %d in the template inflammation-%d.csv,
with the value of i, i.e., 1.
The resulting string is inflammation-1.csv,
which is assigned to the variable file_name.
The disp command prints that string to screen.
The second time around, sprintf generates the string inflammation-2.csv,
which is assigned to the variable file_name,
and printed to screen.
And so on, till i finally refers to the value 12.
Notice that there’s a mistake.
Our files are actually named
inflammation-01.csv, inflammation-02.csv, etc.
To get it right, we have to modify our template:
for idx = 1:12
file_name = sprintf('inflammation-%02d.csv', idx);
disp(file_name);
end
inflammation-01.csv
inflammation-02.csv
inflammation-03.csv
inflammation-04.csv
inflammation-05.csv
inflammation-06.csv
inflammation-07.csv
inflammation-08.csv
inflammation-09.csv
inflammation-10.csv
inflammation-11.csv
inflammation-12.csv
We’ve replaced %d in our earlier template with %02d.
With this,
we’re specifying that we want our data to be displayed
with a minimum width of 2 characters,
and that we want to pad with 0 for data
that isn’t at least 2 digits long.
We’re now ready to modify analyze.m to process multiple data files:
% script analyze_loops.m
for idx = 1:3
% Generate strings for file and image names:
file_name = sprintf('data/inflammation-%02d.csv', idx);
img_name = sprintf ('patient_data-%02d.png', idx);
patient_data = csvread(file_name);
disp(['Maximum inflammation: ', num2str(max(patient_data(:)))]);
disp(['Minimum inflammation: ', num2str(min(patient_data(:)))]);
disp(['Standard deviation: ', num2str(std(patient_data(:)))]);
ave_inflammation = mean(patient_data, 1);
figure('visible', 'off')
subplot(2, 2, 1);
plot(ave_inflammation);
ylabel('average')
subplot(2, 2, 2);
plot(max(patient_data, [], 1));
ylabel('max')
subplot(2, 2, 3);
plot(min(patient_data, [], 1));
ylabel('min')
print('-dpng', img_name);
close();
end
Save the analyze.m script as a new script called analyze_loops.m.
To do this, we go to the Editor tab, click on the arrow below Save,
and then on Save As....
Remember that to run our script,
we simply type in its name in the command line:
analyze_loops
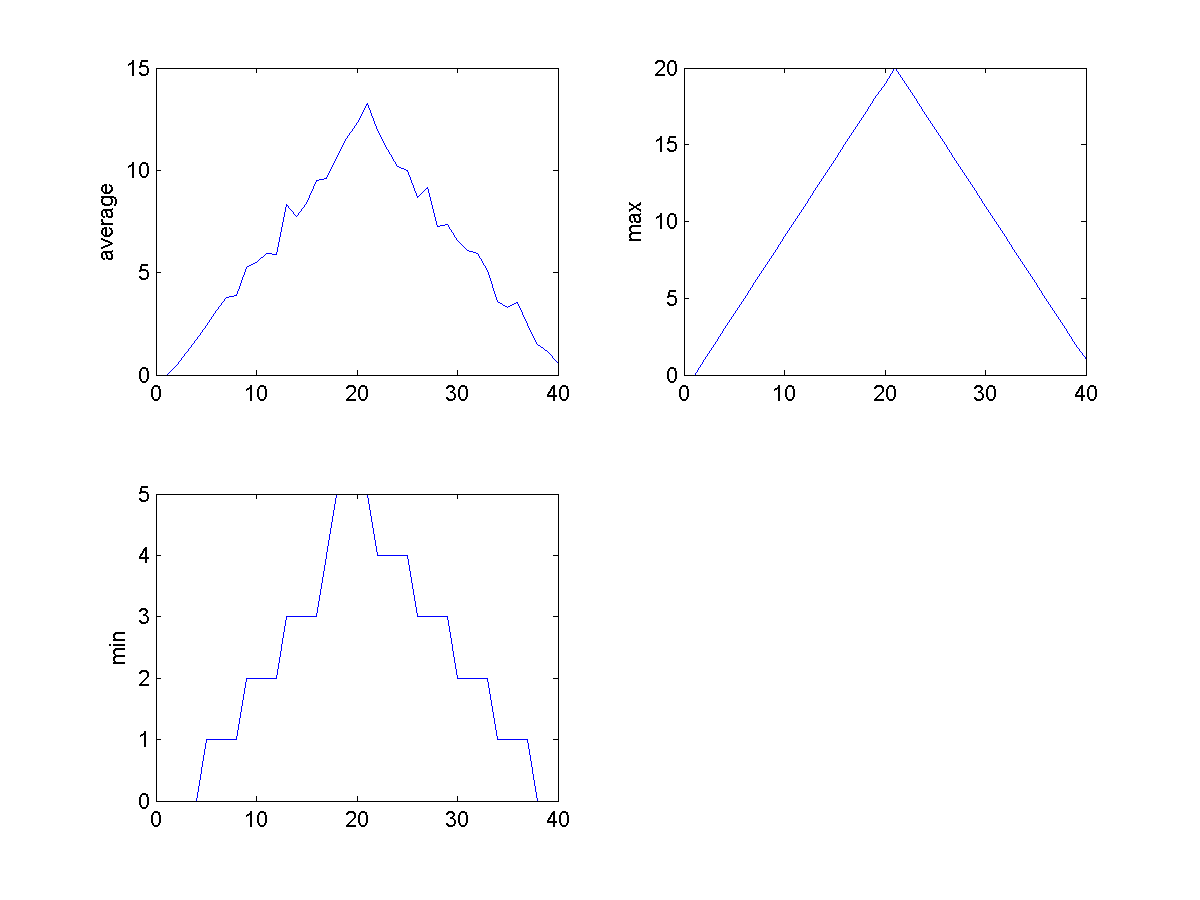
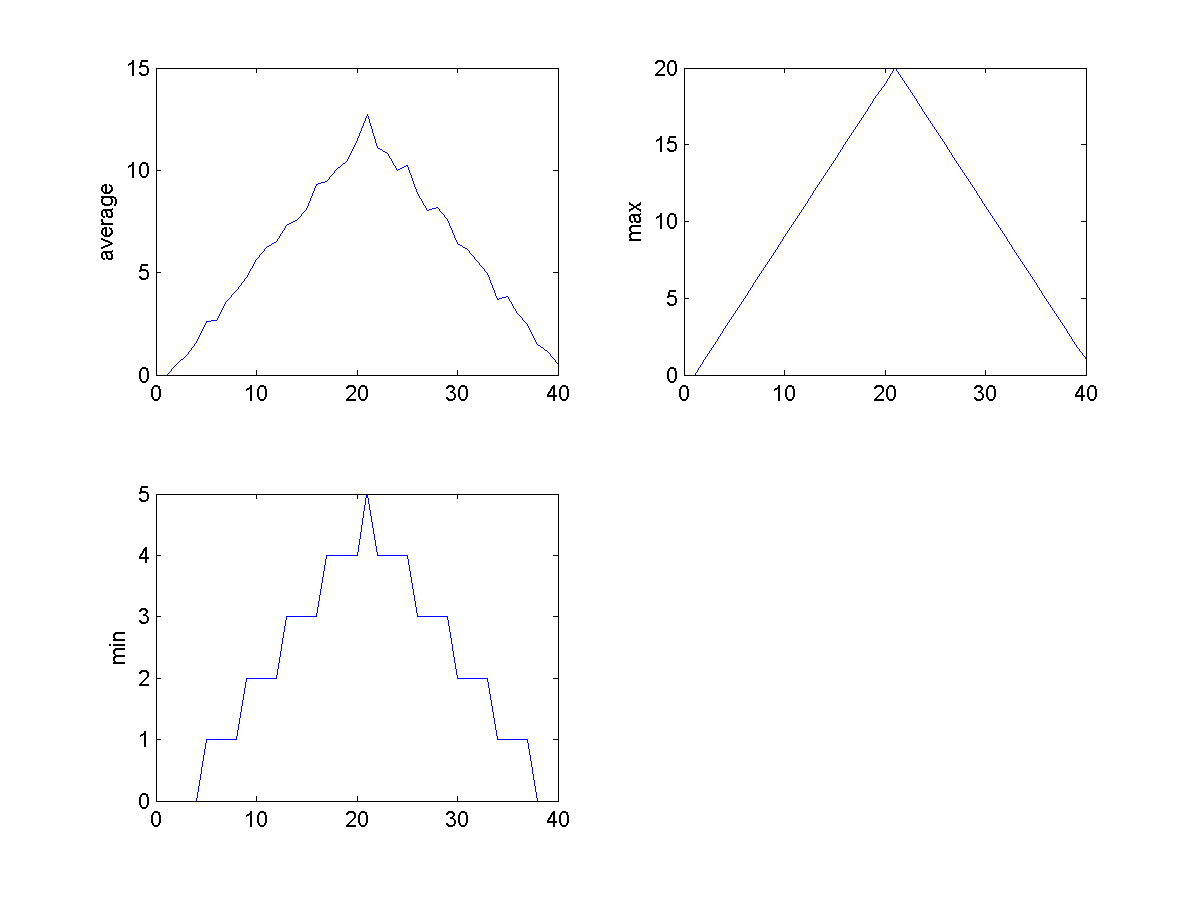
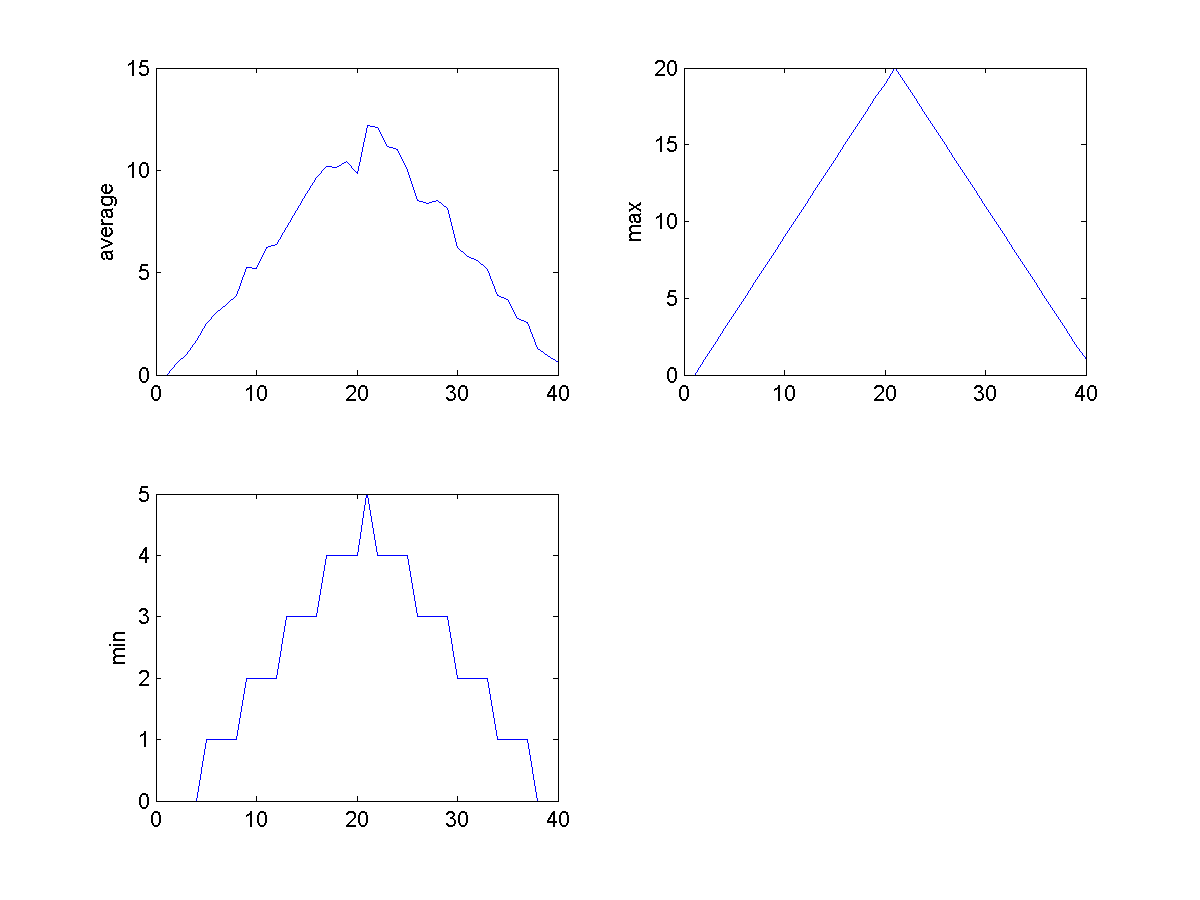
Sure enough, the maxima of these data sets show exactly the same ramp as the first, and their minima show the same staircase structure.
We’ve now automated the analysis and have confirmed that all the data files show the same artifact. This is what we set out to test, and now we can just call one function to do it. With minor modifications, this function could be re-used to check all our future data files.
Another Way to Analyze Multiple Files
In cases where our file names don’t follow such a regular pattern, we might want to process all files that end with a given extension, say
.csv. At the command line we could get this list of files by using a wildcard:ls *.csvWe can also do something similar with Octave, using the
dircommand:files = dir('*.csv')files = 12x1 struct array with fields: name date bytes isdir datenumThe
dircommand returns a special Octave data type called a “struct array”. Each element in this array is a “struct”, containing information about a single file in the form of “fields”.To access the “name” field of, say, the first file, we can do the following:
name = files(1).name; disp(name)inflammation-01.csvTo get the modification date of the third file, we can do:
mod_date = files(3).date; disp(mod_date)26-Jul-2015 22:24:31Information about the other fields like
bytesandisdiris available in the documentation of thedirfunction:help dirUsing
dir, rewrite theanalyzescript to analyze allcsvfiles in the current directory.
GNU Octave
Lastly, in the above trick using
lswith the wildcard*, another small Octave/MATLAB difference shows up. In Octave, the value returned byfilestr = ls('path/to/data/*.csv')is an array of strings, so we can loop overfilestrdirectly without the need to split it withstrsplit.
Key Points
Use
forto create a loop that repeats one or more operations.