Bagus Tris Atmaja
Research Theme
My research goals are aimed at extracting knowledge from acoustic information (aka acoustic features). Examples of this theme include: speech emotion recognition, abnormal sound detection, and audio classification. Moreover, the research can be extended to vibration signals. My approaches to achieve these goals are defined by: (1) data-driven approach (instead of physical modeling), (2) focus on practical implementation (not necessarily following human mechanisms), and robustness (how stable/consistent the model is given any perturbation instead of correctness). For me, science should be evidence-based, implementable, and consistent. My research is result-oriented instead of process-oriented. This doesn’t mean that the process (physical phenomena, modeling, math, and algorithms) is not important. If we understand the process very well, the solution may appear by itself. Still, there must be a reason (rationale) for doing such research. Then, I judge my research mainly based on the results. My research contributes to developing technologies to solve issues in Society 5.0 (What is Society 5.0? Read here in Indonesian language).
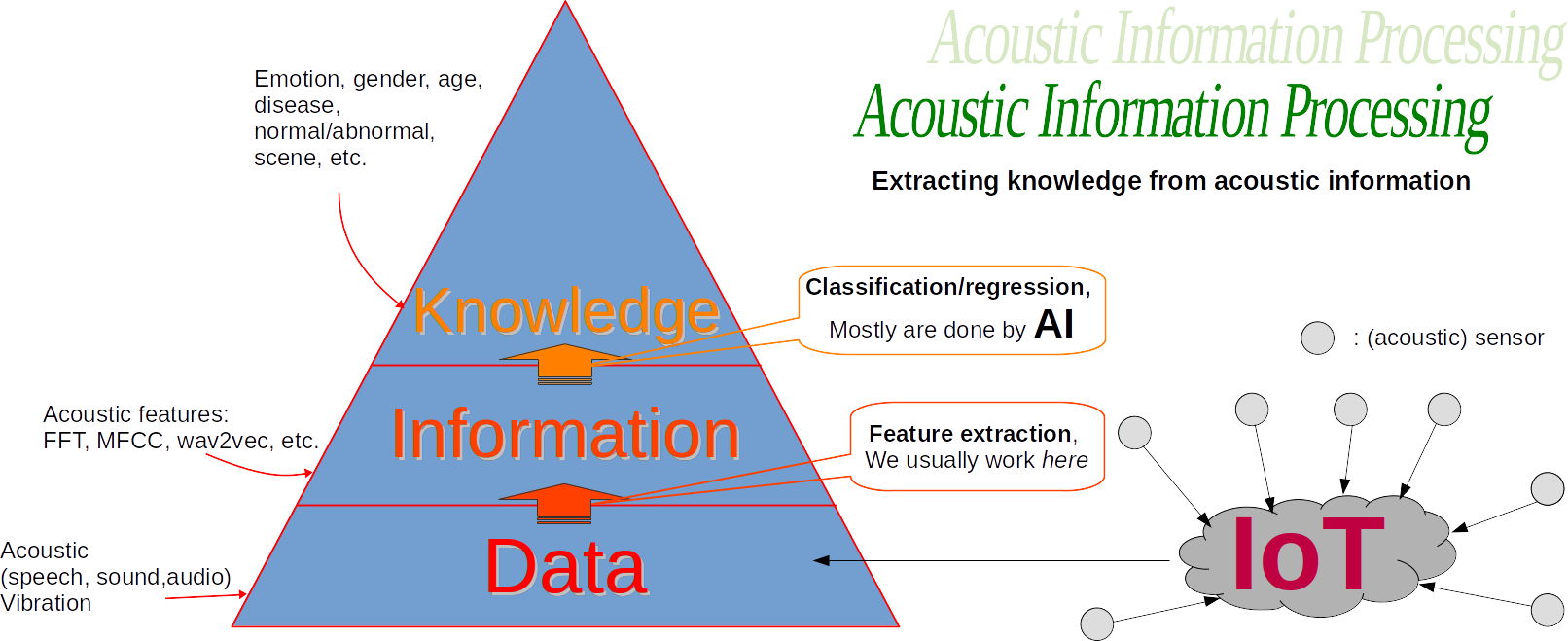
The following are research themes that I offer, particularly (but NOT limited to) Engineering Physics students at ITS.
For undergraduate level, I will try to provide the baseline method, and you will improve the results using your proposed method.
- Speech emotion recognition using multilayer perceptron with CCC loss, dataset: IEMOCAP
- Indonesian speech recognition using Wav2Vec2/Hubert/WavLM/UniSpeech-SAT, etc.
- Toward universal acoustic features for multi-corpus speech emotion recognition, 30+ datasets.
4. Predicting Alzheimer’s disease using speech analysis. - Development of Calfem-Python
- Development of Vibration Toolbox
7. Abnormal sound detection for predictive maintenance (the method is from you/your idea), dataset: DCASE - Indonesian emotional speech synthesis using FastSpeech
9. COVID-19 diagnosis using COUGH sound with deep learning - COVID-19 diagnosis using SPEECH sound with deep learning, dataset: ComParE CSS 2021
- Predicting pathological voice disorders with speech processing techniques, dataset: SVD, Voiced, HUPA
- Detection of emotion intensity in non-speech sounds (laughter, crying, etc.)
- Detecting/predicting stuttering (bahasa: gagap) in speech with machine learning
- Predicting the intensities of seven self-reported emotions (Adoration, Amusement, Anxiety, Disgust, Empathic Pain, Fear, Surprise) from user-generated reactions to emotionally evocative videos
- Few-shot learning on acoustic data to capture 10 dimensions of emotion reliably perceived in distinct vocal bursts: Awe, Excitement, Amusement, Awkwardness, Fear, Horror, Distress, Triumph, Sadness and Surprise
- Multimodal learning (audio+video+text) to capture 10 dimensions of emotion reliably perceived in distinct vocal bursts: Awe, Excitement, Amusement, Awkwardness, Fear, Horror, Distress, Triumph, Sadness and Surprise
- Inferring self-reported emotion from multimodal expression, using multi-output regression to predict fine-grained self-report annotations of seven ‘in-the-wild’ emotional experiences
Other topics/themes:
Read my papers. Usually, I write down the remaining tasks for future work in that topic. For master’s level, you can also propose your research theme. Contact me by email for details.
Typical Timeline:
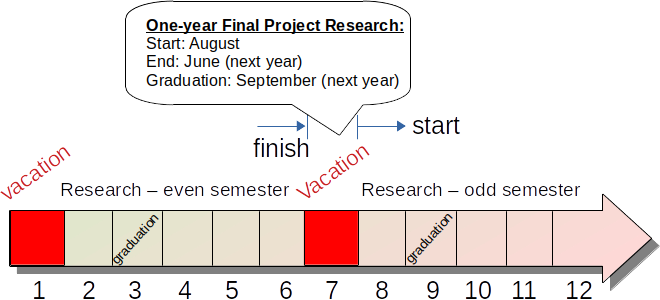
The timeline is ideal for undergraduate (S1) students; it can be adapted for master’s (S2) and PhD (S3, three years of research from the beginning) levels.
Contact email: bagus[at]ep.its.ac.id