研究
研究テーマ
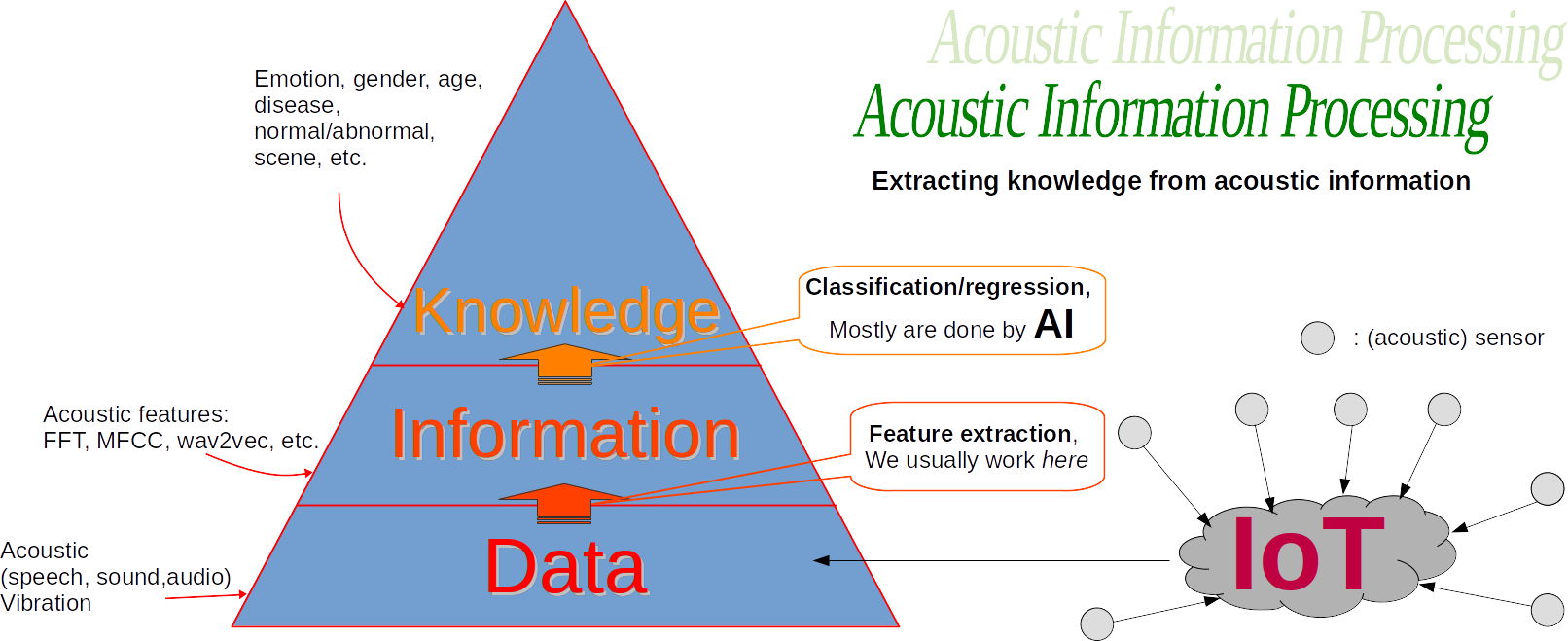
私の研究目標は、音響情報(音響特徴量)から知識を抽出することです。具体的には、音声感情認識、異常音検出、音声分類などが挙げられます。さらに、振動信号への応用も行っています。研究のアプローチとして:(1) データ駆動型アプローチ(物理モデリングより)、(2) 実装可能性を重視(必ずしも人間のメカニズムに従わない)、(3) 頑健性(正確さより、乱れがあっても安定・一貫したモデルか)を重視しています。科学はエビデンスに基づき、実装可能で、一貫性があるべきと考えます。
提供中の研究テーマ
以下は過去に提供してきた研究テーマです:
- CCCロスを用いた多層パーセプトロンによる音声感情認識(データセット:IEMOCAP)
- Wav2Vec2/Hubert/WavLM/UniSpeech-SATによるインドネシア語音声認識
- 複数コーパス音声感情認識のための汎用音響特徴量の探求(30以上のデータセット)
- Calfem-Pythonの開発
- Vibration Toolboxの開発
- FastSpeechによるインドネシア語感情音声合成
- 深層学習を用いた音声によるCOVID-19診断(データセット:ComParE CSS 2021)
- 音声処理技術による病的声障害の予測(データセット:SVD, Voiced, HUPA)
- 非音声音(笑い声、泣き声など)における感情強度の検出
- 機械学習によるどもり(吃音)の検出・予測
- 感情的動画に対するユーザー反応から7つの自己報告感情強度を予測
- 独自の発声バーストで認知される10次元の感情をキャプチャするFew-shot学習
- 発声バーストで認知される感情のマルチモーダル(音声+映像+テキスト)学習
- マルチ出力回帰による感情の自己報告アノテーション予測
学部生レベルには、ベースライン手法を提供し、提案手法による改善を目指します。
標準的なタイムライン

緑:最も集中して作業し、遊ぶフェーズ;青:さらに作業するフェーズ;黄:作業しつつ遊ぶフェーズ
タイムラインは1年単位;学部生(S1、最終学年)、修士(S2、2年間)、博士(S3、研究開始から3年間)に対応。
指導方針
修士生には特別な要件はありませんが、博士生は入学前に1本の論文発表が必要です(IEEE Xploreまたは同等レベル)。信号処理と機械学習の強固な知識を持つ学生を優遇します。NkululekoまたはSpeechainツールキットを使用した経験のある、研究に対して高い動機と情熱を持つ学生を好みます。修士生は私が提供する研究テーマで取り組み、博士生は独自のテーマを提案することが期待されます。定期的なミーティング(ゼミ、セミナー等)が研究の進捗・課題・次のステップを議論する鍵です。
連絡先
研究コラボレーションについては、英語ページもご参照ください。メールにてご連絡ください:bagustris[at]outlook.com